Big Data & bruteforce
Overview
El Big Data es la herramienta que nos permite manejar y procesar la enorme cantidad de datos a la que tenemos acceso en la actualidad.

Su aplicación es diversa, abarcando sectores como la atención médica, el marketing, la gestión de proyectos y la seguridad de la información, entre otros.
Se caracteriza por las 3V: Volumen, Velocidad y Variedad. Hoy en día, tenemos acceso a vastas fuentes de información que necesitamos procesar y normalizar para aprovechar su potencial.
El procesamiento eficiente de estos datos nos abre las puertas a los sistemas de inteligencia empresarial y nos permite pasar de ser una empresa dirigida por la intuición de sus directivos a una empresa “data driven”, donde las decisiones se basan en la información empírica disponible.
Laboratorio
Para el ejemplo que se presenta, dado que contiene una cantidad de datos pequeña (14.344.391 registros) y el uso de un cifrado fácil de calcular (MD5), podemos ejecutar el código proporcionado en Google Colab sin mayor problema. Sin embargo, para comprender cómo la paralelización de los cálculos nos ayuda a obtener resultados en un tiempo más corto, lo ideal es crear un clúster. Una opción eficiente y no muy complicada es la combinación de Hadoop y Spark, ambos proyectos de Apache.
Hadoop
Hadoop es un framework de código abierto que permite almacenar y procesar grandes conjuntos de datos (Big Data) de forma distribuida en Clusters.

Sus características principales son:
Escalabilidad: Puede trabajar con miles de nodos en red y petabytes de datos.
Tolerancia a fallos: Detecta y recupera automáticamente fallos en los nodos del clúster.
Procesamiento en paralelo: Divide las tareas en pequeños fragmentos que se ejecutan en paralelo en los nodos del clúster.
Almacenamiento sin restricciones: Soporta una gran variedad de tipos de datos, incluyendo datos estructurados, semiestructurados y no estructurados.
Costo-efectivo: Puede ejecutarse en hardware de bajo costo.
Hadoop se compone de dos componentes principales:
HDFS (Hadoop Distributed File System): Un sistema de archivos distribuido para almacenar grandes conjuntos de datos.
MapReduce: Un modelo de programación para procesar grandes conjuntos de datos en paralelo.
Puedes obtener información más detallada en Hadoop.
Spark
Spark es un motor de análisis unificado de código abierto para procesar grandes conjuntos de datos (Big Data) de forma distribuida en Clusters.

Sus características principales son:
Velocidad: es mucho más rápido que Hadoop MapReduce para muchos tipos de tareas de procesamiento de datos.
Facilidad de uso: proporciona una API de alto nivel que facilita escribir aplicaciones de análisis de datos.
Flexibilidad: es compatible con una amplia variedad de tipos de datos, formatos de archivo y lenguajes de programación (Scala, Python, Java, R).
Escalabilidad: puede escalarse a miles de nodos en red y petabytes de datos.
Tolerancia a fallos: detecta y recupera automáticamente fallos en los nodos del clúster.
Por otro lado, se complementa muy bien con hadoop, aprovechando las mejores características de cada uno de ellos.
Puedes obtener información más detallada en Spark.
PySpark
PySpark es la API de Python para Apache Spark, lo que significa que te permite utilizar la potencia de Spark para procesar grandes conjuntos de datos desde un entorno Python familiar.
Password bruteforce
Dada la naturaleza de este blog y las capacidades de Spark, he decidido enfocar nuestro ejemplo en la seguridad informática, específicamente en la técnica de fuerza bruta sobre una contraseña.
En la fuerza bruta sobre credenciales, el programa convierte texto al tipo de cifrado que estamos utilizando y lo compara con el hash obtenido. Por ejemplo, si hemos obtenido el hash MD5 “f806fc5a2a0d5ba2471600758452799c” y queremos obtener la clave en texto plano, debemos cifrar las distintas palabras de un diccionario y comparar los hashes hasta encontrar una coincidencia.
PySpark nos permite realizar esto de manera sencilla, como se muestra en el siguiente código de ejemplo.
Primero, descargaremos un diccionario. Hemos elegido “rockyou”, que es habitual en las primeras fases de un ataque de fuerza bruta.
1 | wget https://github.com/brannondorsey/naive-hashcat/releases/download/data/rockyou.txt |
Luego, instalaremos las librerías de Python necesarias para trabajar con PySpark.
1 | pip install -q findspark |
A continuación, importaremos las librerías necesarias, tanto las de PySpark como las de hashlib, que nos permitirá realizar el cifrado MD5 que usaremos en el ejemplo.
1 | from pyspark.sql import SparkSession |
Definimos la función de cifrado, en este caso MD5, pero simplemente modificando esta función podemos usar el código para otros cifrados como NTML, SHA-1, etc.
1 | def cifrar_md5(x): |
Crearemos la sesión de Spark, leeremos el diccionario que hemos descargado (rockyou.txt) y aplicaremos la función lambda que cifrará todas las palabras contenidas en el diccionario.
1 | # Session de spark |
Usaremos una función de filtro de PySpark para buscar el hash que nos interesa, proporcionándonos su equivalencia en texto plano.
1 | rdd_resp = palabras_cifradas_rdd.filter(lambda x: x[1] == 'f806fc5a2a0d5ba2471600758452799c') |
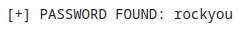
Una de las características de Spark es que el costo computacional es mínimo hasta que solicitamos los datos con la instrucción collect(). Es en ese momento cuando Spark paraleliza el proceso y nos proporciona los datos.
Otra estrategia podría ser procesar el diccionario completo y almacenarlo para poder consultarlo más rápidamente cuando sea necesario, al estilo de las “rainbow tables”.
En este caso, una vez cifrado el texto, forzaremos el uso de un único archivo para facilitar su consulta posterior.
1 | # Reducir a 1 RDD (para almacenar en un único fichero) |
Podemos consultar las primeras líneas de su contenido de la siguiente manera:
1 | new_rdd = sc.textFile('/content/rockyou-map-md5/part-00000') |

Conclusiones
Con Hadoop y Spark, y las técnicas de Big Data, podemos aprovechar el poder de la información que nos proporciona la era digital. Aunque no son las únicas herramientas disponibles, son un buen punto de partida para iniciarse en el análisis de datos y en las técnicas del Big Data.
A través del análisis de datos, las empresas pueden tomar decisiones más inteligentes, optimizar sus procesos y descubrir nuevas oportunidades de negocio.
Por otro lado, haciendo uso de estas técnicas, podemos procesar datos para otros usos, como el que hemos visto en el ejemplo.
Hasta aquí el post de hoy. Espero haya sido de vuestro interés.
No dudéis en contactar mediante el formulario para hacerme llegar vuestros comentarios.