datos y metadatos
Overview
Vivimos en un mundo donde los datos han ido obteniendo cada vez mayor importancia. Es habitual oír el concepto datadriven company para referirnos a compañías que emplean los datos en la toma de decisiones, también escuchamos habitualmente que las grandes compañías tecnológicas mercadean con nuestros datos o que se han usado los datos de facebook, por Cambridge analytica, para influir en las elecciones de los Estados Unidos de América del 2016, expuesto de forma contundente en el documental de Netflix El gran hackeo.
También es habitual hablar sobre la cantidad de datos que generamos diariamente en el mundo digital y de la importancia de los metadatos.
No puedo continuar sin definir antes el significado de la palabra metadato. Palabra de origen griego, meta se puede referir a después de, más allá de o literalmente sobre que es la que más se ajusta al sentido que se le da en el campo de la informática. Así que podemos decir que un metadato es un dato sobre un dato, nos aporta una información que acompaña al dato.
Por ejemplo, en una imagen digital, el dato es la imagen, los metadatos son la hora en la que se ha capturado la imagen, tiempo de exposición, apertura del obturador, marca y modelo de la cámara o teléfono con la que se ha obtenido la imagen y la posición GPS. Como podemos observar, podemos extraer gran cantidad de metadatos que ayudan a los sistemas de información a gestionar el dato proporcionado información relativa al mismo.
Los metadatos se emplean a hoy en día para múltiples objetivos, proporcionado un contexto, en ocasiones extremadamente detallado, del dato en si.
Como ejemplo podemos listar algunos de los usos más habituales, tanto de los datos como de los metadatos.
Forense
En el caso de la informática forense en muchas ocasiones el metadato es más importante que el dato en sí, ya que es el metadato el que puede proporcionarnos un contexto para ubicar una acción o individuo en un lugar concreto en un momento especifico.
Marketing
Es muy útil para la creación de perfiles, tanto los datos como los metadatos que sin ser conscientes proporcionamos a diario, ya sea en las publicaciones que realizamos en nuestras redes sociales o en las interacciones que realizamos con apps o aplicaciones web.
Proporcionamos normalmente de forma inadvertida, hábitos respecto a los horarios en los que publicamos o consultamos servicios, si lo realizamos desde un dispositivo móvil o desde un ordenador, la propia marca y modelo de nuestro dispositivo, la ubicación en la que nos encontramos, etc. Con toda esta información somos clasificados en perfiles de edad, tipo de consumo, hábitos, etc. Y vendidos a agencias para que nos propongan publicidad a medida.
Este es el negocio de las mayores compañías tecnológicas, que consiguen grandes beneficios por los ingresos generados por la gestión de la publicidad.
Seguridad
En seguridad de la información para un atacante puede ser muy interesante conocer, por ejemplo, que software usamos para la edición de imágenes o video, editor de texto o sistema operativo. Igual que en ejemplos anteriores, el atacante usará la información obtenida para obtener ventaja o aprovecharse de alguna brecha de seguridad conocida. Cuanta más información puedan obtener, más eficiente serán sus ataques, ya sean directos o creando campañas de phishing dirigidas.
También a la hora de defender nuestros sistemas tanto los datos como los metadatos pueden ofrecernos información que nos puede ayudar a identificar quien es el autor del ataque que estamos recibiendo, en este escenario el autor intentará siempre ocultar su identidad, pero si no ha sido cuidadoso nos puede proporcionar indicios que nos permitan identificarle.
Propiedad intelectual
Otro caso interesante es el de la protección de la propiedad intelectual. Como ya hemos mencionado en repetidas ocasiones, cuando generamos un fichero, de este se pueden obtener los datos del software con el que éste se ha creado. Pongamos por ejemplo, que tenemos un periódico online y que no hemos sido cuidadosos con los metadatos de las imágenes publicadas en él. Si el fabricante del software empleado advierte que no estamos pagando sus licencias lo tiene fácil para poder incriminarnos.
Herramientas para extracción de metadatos
Existen varias herramientas que nos permiten extraer los metadatos de distintos tipos de ficheros o como veremos en el siguiente ejemplo obtiene gran cantidad de información de forma automatizada de cualquier dominio web.
Foca
En entornos Windows la más conocida es foca, una herramienta muy orientada a los test de intrusión, que nos permite de forma simple obtener gran cantidad de datos de un dominio proporcionado y que usa distintas técnicas para maximizar los resultados.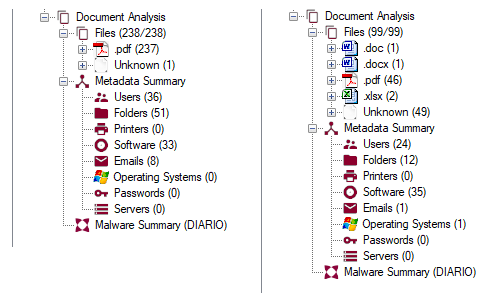
En esta ocasión su uso no es ilegal, ya que lo único que estamos haciendo es acceder a información publicada en internet por su propietario.
La podéis descargar desde su github FOCA
Como se puede observar en las imágenes que se muestran a continuación la información obtenida por foca, únicamente proporcionado un dominio web, en cada uno de los casos es abundante y muy relevante. Incluyo únicamente el resumen de los datos obtenidos, pero como vemos en ambos casos se han obtenido nombres de usuarios, carpetas compartidas, software con el que se han creado los documentos analizados, correos electrónicos y sistemas operativos.
Los ejemplos de las imágenes corresponden a un periódico digital y a un partido político. Son ejemplos de alta exposición ya que publican mucha información de forma periódica.
En este caso no entraremos en el uso de la herramienta ya que esta es muy intuitiva y ya está ampliamente documentada.
Exif
En entornos Linux si queremos obtener los metadatos de una imagen sin duda el más conocido es exif, aunque hay también otras herramientas como ImageMagick que nos proporcionan también mucha información. Ambas son herramientas de liana de comandos.
En el ejemlo ejecutamos exif para extraer los datos de una imagen descargada de internet.
1 | ~:$ exif example.jpg |
Como podemos observar se obtiene muchísima información de la misma imagen.
La imagen fue tomada en el 14 de octubre del 2017 a las 11:16 a.m. con una cámara GoPro HERO4 Silver y fue editada posteriormente con GIMP 2.8.10, un software de edición de imágenes open source.
En este ejemplo no hemos obtenido la posición GPS, pero en el caso de que dispongamos la opción activa en el momento de realizar la fotografía esta seria también adquirida.
Otro ejemplo es file, como vemos en si ejecución nos aporta también información relevante.
1 | ~:$ file example.jpg |
Igual que de una imagen podemos obtener toda esta información se pueden aplicar técnicas para obtener los metadatos de documentos ofimáticos, de comunicaciones digitales como las llamadas o los mensajes de WhatsApp, Telegram, Twitter, compras online o con tarjeta de crédito, navegación web … las fuentes de información que alimentamos constantemente inconscientemente son ingentes. Y uso el termino inconsciente en el mal sentido de la palabra, tendríamos, todos, que empezar a tomar consciencia de los datos que proporcionamos y aplicar técnicas de higiene digital que nos ayuden a dejar una huella digital menor.
Herramientas para extracción de datos
Cuando desde el campo de la seguridad de la información hablamos de la obtención de datos se suele hacer referencia a OSINT (open source intelligence), que de forma simplificada podemos decir que se basa en el uso de información pública para generar inteligencia. Solo como apunte, que la información sea pública no quiere decir que esta se haya publicado conscientemente.
Como veremos en los próximos ejemplos la información en muchos de los casos la obtenemos de forma indirecta, mediante registros de entidades, portales o protocolos necesarios para el funcionamiento de los servicios.
Osint framework
Antes de proponer algunos ejemplos, una página que no podemos pasar por alto a la hora de hablar de OSINT es osintframework.com, una página que nos muestra distintas páginas donde obtener información clasificada por temáticas.
Podéis consultar también otro portal osintessentials que dispone también de algunas fuentes de información interesantes.
RIPE (Network Coordination Centrer)
RIPE es el organismo a nivel europeo que gestiona los rangos IP . Es muy útil para detectar redes privadas que tal vez no se hayan vinculado al dominio de la compañía. Como con la mayoría de las técnicas OSINT lo que pretendemos es ampliar la superficie de ataque.
1 | ~:$ wget https://ftp.ripe.net/ripe/dbase/ripe.db.gz |
whois
Los usuarios de Linux disponemos de comandos como whois que nos proporciona en el terminal la información de registro de los dominios, es casi un paso obligatorio al iniciar cualquier investigación, aunque como veremos en el siguiente ejemplo, si se han aplicado las políticas de privacidad no nos ofrece mucha información.
1 | ~:$ whois playingwith.info |
Para los que no dispongáis de un sistema Linux podéis consultar esta misma información en servicios como who.is.
dnsdumpster
Este es un portal que no ayuda a obtener información de los servidores de nombres de un dominio.
Los servidores de nombres son los encargados de traducir las direcciones web o url, fácilmente comprensibles, a direcciones IP, necesarias para el funcionamiento de las redes y de internet.
Podemos acceder al portal desde dnsdumpster y buscar información de cualquier dominio.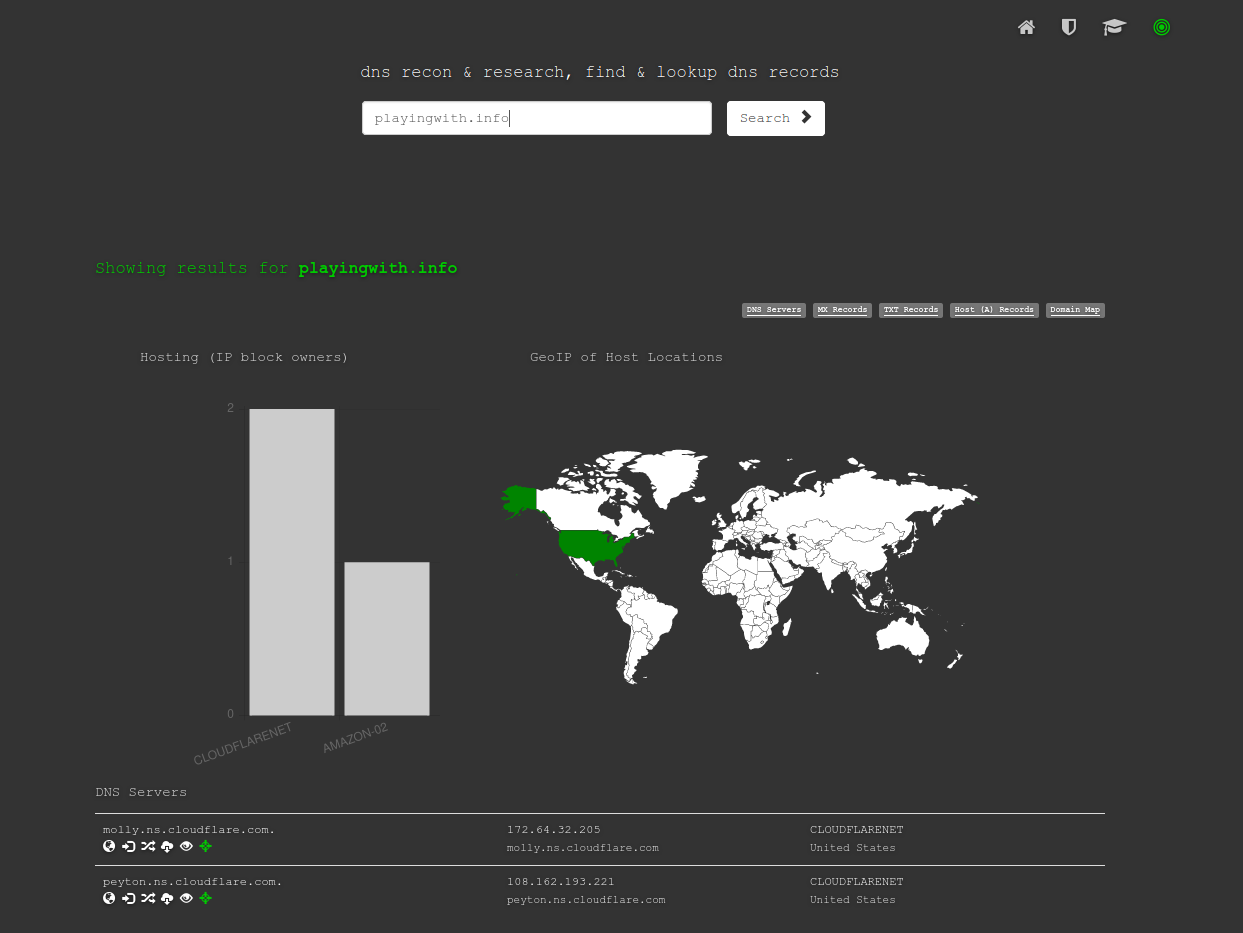
En el ejemplo, la búsqueda del dominio de este mismo blog, podemos observar donde se encuentran los servidores que sirven la web. He de reconocer que en este caso hay cierto truco que no es el objeto de este post, pero sirve igualmente para ilustrar la potencia del portal.
Shodan
Una vez conocemos los dominios e IP’s expuestos, shodan es sin duda el portal donde podemos obtener información de los servicios publicados en internet. Sin duda se merecería un post completo, pero en esta ocasión solo indicaremos su potencial para el descubrimiento de servicios.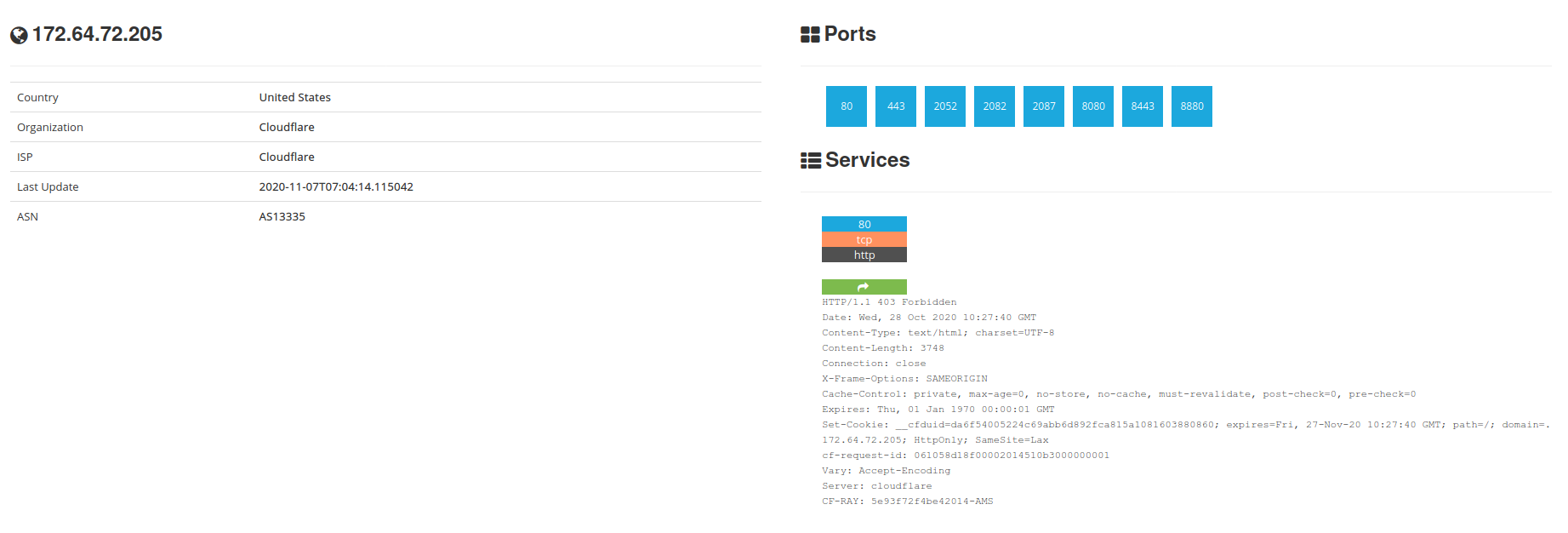
En el ejemplo analizamos una de las IP’s proporcionadas por dnsdumpster. Como vemos tiene expuestos bastantes servicios que a los técnicos nos proporciona una idea clara de qué servicio provee dicho servidor.
No entraremos en el detalle del mismo dado que el objeto del post es la información expuesta, no su posterior tratamiento.
archive.org
Ya para finalizar la parte relativa a las infraestructuras, otro portal interesante es archive, este portal empezó a archivar páginas web desde 1996, de las que va tomando instantáneas periódicamente.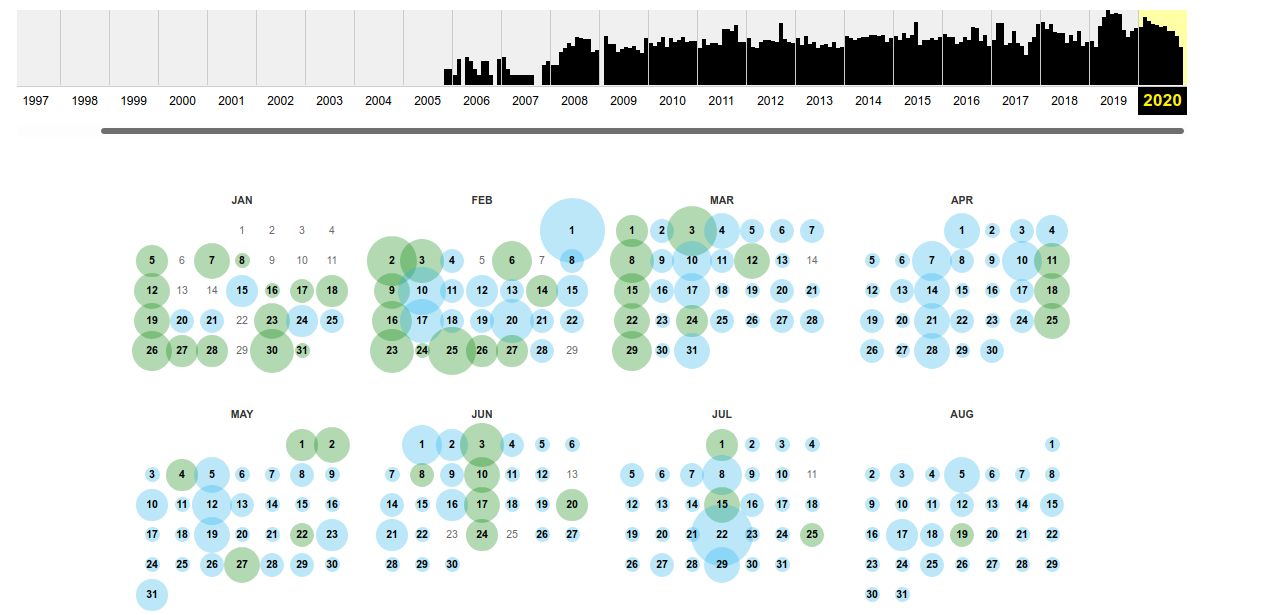
Es interesante para ver la evolución de las páginas web, buscar información que actualmente ya no esté disponible o tratar de obtener datos de agluna mala configuración anterior.
theHarvaster
Otra herramienta muy interesante para obtención de información, en este caso de dominios es theHarvaster. Esta herramienta nos proporciona correos electrónicos, IP’s y subdominios del dominio que le especifiquemos.
Permite buscar en distintos motores de búsqueda como Bing, duckduckgo o Google, el cual suele bloquearla de vez en cuando. Y en otras plataformas como LinkedIn, Twitter, trello, etc
1 | ~:$ theHarvester -d playingwith.info -l 500 -b all |
Es cierto que no siempre es exitosa, pero nos puede ofrecer información muy valiosa.
La información obtenida de los elementos de la infraestructura resulta muy interesante sobre todo para los que somos de perfil técnico, pero me parece muy relevante la información que se puede obtener de nuestras cuentas, ya sean personales o profesionales. A continuación, algunos ejemplos al respecto.
Examinaremos algunos ejemplos, pero existen multitud de herramientas y cada día aparecen de nuevas.
GHunt
Esta aplicación, que podéis obtener desde su github GHunt es un claro ejemplo. Nos ofrece datos sobre cualquier cuenta de google que le proporcionemos como:
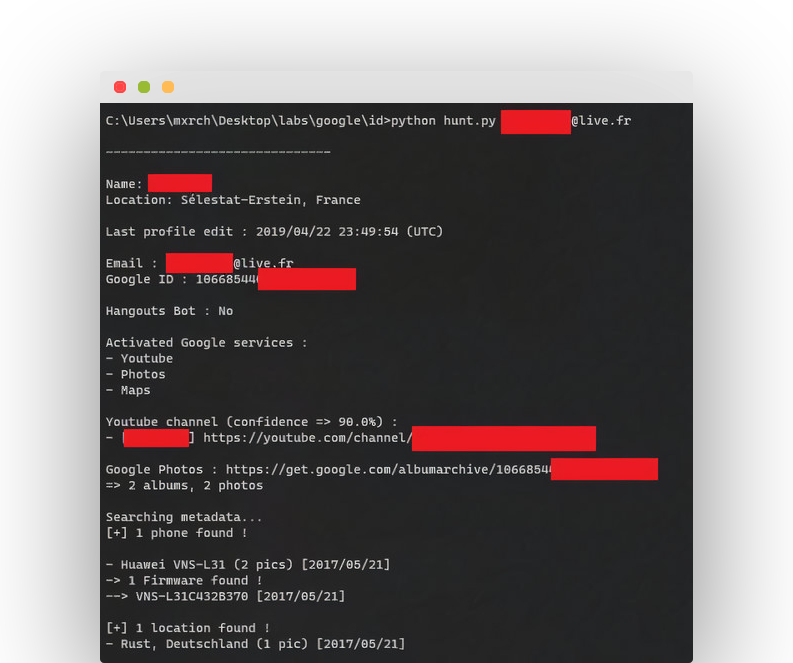 Según la configuración de privacidad que hayamos aplicado en nuestra cuenta de google la información visible será escasa o abundante … También apuntar, que al menos en la imagen del perfil, google se preocupa de eliminar los metadatos.
Según la configuración de privacidad que hayamos aplicado en nuestra cuenta de google la información visible será escasa o abundante … También apuntar, que al menos en la imagen del perfil, google se preocupa de eliminar los metadatos.
truthnest
Este portal nos permite analizar los datos de cualquier cuenta de twitter, es muy interesante para ver a qué horas lo usa, sobre qué opina, en qué sentido …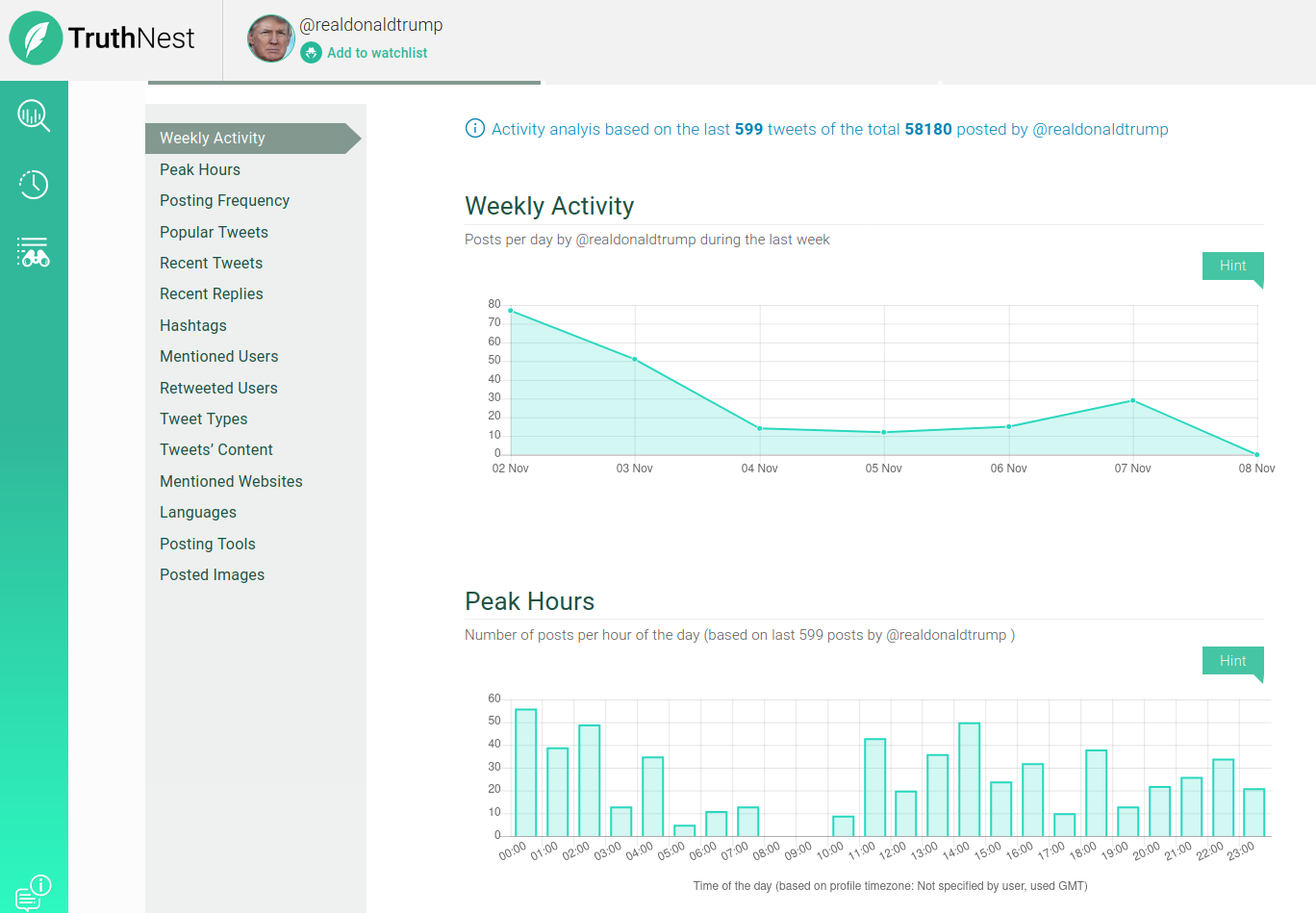
Para usarla solo nos tenemos que logar en el portal truthnest y proporcionar nuestra cuenta.
Como hemos visto a lo largo del post proporcionamos una gran cantidad de datos a la red, algunos los conocemos, otros hasta ahora los desconocíamos y muchos seguro que nos pasan desapercibidos. La digitalización de nuestra vida nos aporta muchas ventajas, pero también proporciona a quienes la saben aprovechar formas de trazarnos, clasificarnos, localizarnos y posiblemente manipularnos. La línea que separa, el uso de los datos para la mejora de la experiencia del usuario, a la manipulación del mismo, es muy delgada.
Por nuestra parte el uso coherente de las herramientas como los dispositivos móviles, redes sociales, correo electrónico, etc., es necesario para que no nos convirtamos esclavos de las mismas. Como es obvio los fabricantes de software hacen aplicaciones atractivas que compiten para captar nuestra atención y somos nosotros los que tenemos que decidir, conscientemente, cuanto tiempo les queremos dedicar.
Por otro lado, tenemos que ser conscientes de que es muy poco probable que nos ofrezcan servicios gratuitos sin ningún coste. Todos nosotros somos consumidores de plataformas, que como hemos dicho ya en la introducción del post, a cambio de ofrecernos sus servicios comercializan con nuestros datos. Si lo aceptamos, todo está bien, pero es importante que tengamos consciencia de ello.
En la misma línea he escuchado, en más de una ocasión, personas que dicen, yo no tengo nada que esconder, no me importa que vean mis datos, y ésta es para mí la más peligrosa de las percepciones, ya que lo importante no es que accedan a tus datos sinó lo que son capaces de hacer con ellos. Con mucha probabilidad será una IA la que clasifique la información de forma masiva y como hemos visto en el caso ya comentado de Cambridge analytica la terminen empleando para influir en tus propias decisiones.
Propongo, en la línea de estas últimas líneas, otro documental de Netflix El dilema de las redes, donde los que formaron parte del diseño de algunas de las grandes plataformas, comentan sus impresiones viendo el sistema en perspectiva.
Me pongo en la piel de una aseguradora que pueda disponer de acceso a los datos proporcionados, por ejemplo, de los datos de salud que nos ofrecen nuestros dispositivos móviles. ¿Aumentaría las cuotas a los clientes con vidas sedentarias?
No quiero con este último alegato desalentar el uso de la tecnología o de las grandes plataformas de servicios online, al contrario, hay herramientas increíbles que nos pueden facilitar mucho la vida y la interacción con quienes están lejos. Pero tenemos que ser conscientes del coste que tienen y del tiempo que les dedicamos.
Hasta aquí el post de hoy. Espero haya sido de vuestro interés.
No dudéis en contactar mediante el formulario para hacerme llegar vuestros comentarios.